发布时间:2025-12-30 来源:芯联汇

当 LLM 推理被内存墙与能耗成本锁死,把最耗带宽的计算下沉到内存,正在成为现实解法
最近小编系统看了一份来自 SK hynix 海力士 的技术材料,题目是《AI-Specific Computing Memory Solution:From AiM Device to Heterogeneous AiMX-xPU System for Comprehensive LLM Inference》。
在真正读完之前,小编对 LLM 推理的直觉判断,其实很简单:模型大了,算力不够,那就继续堆 GPU。
但把这份材料从头到尾消化完之后,小编反而越来越确定一件事:
LLM 推理真正卡住的,已经不是算力上限,而是内存墙叠加能耗墙。
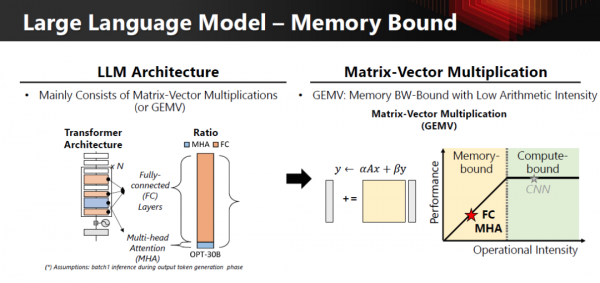
SK hynix 海力士 在材料中先做了一件非常重要的事:把 Transformer 推理阶段的计算拆开来看。
尤其是 Multi-Head Attention(MHA),几乎始终是 GEMV
而 GEMV 有一个无法回避的工程事实:算术强度极低,天然 memory-bound。
把这一点用工程特性摊开,其实就一目了然了:
只要 LLM 推理的关键路径还是 MHA + GEMV,单纯堆算力,永远跨不过内存墙。
真正让这件事变成“架构级问题”的,是 成本和能耗。
SK hynix 海力士 在材料里反复强调:LLM 推理已经成为 OPEX 驱动型负载。
今天的 LLM 推理,不是“跑不动”,而是“跑得越来越贵”。
也正是在这个前提下,小编才真正理解了SK hynix 海力士 推 AiM(Accelerator-in-Memory) 的工程逻辑。
AiM 并不是“再造一个加速器”,而是做了一件很克制的事情:
把最消耗带宽、最浪费能耗的计算,直接放进内存内部完成。
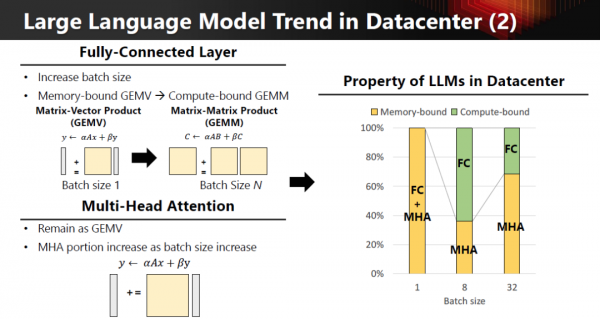
对比传统架构和 AiM 架构,差异其实非常清晰:
AiM 不是为了“算得更快”,而是为了“少做最浪费系统能量的事情”。
SK hynix 海力士 在材料中反复强调一个容易被误解的点:
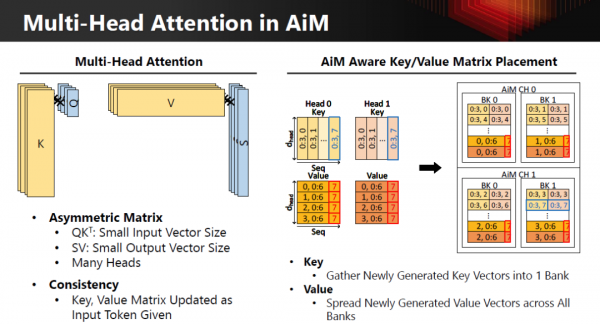
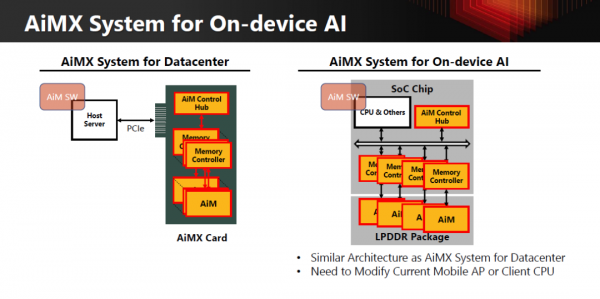
真正的目标,是构建一个 AiMX-xPU 的异构系统:
GPU / xPU:继续负责算术强度高的 GEMM / FC
AiMX(AiM Card):专门接管 GEMV / MHA
系统层面做算子分工,而不是让 GPU 单点硬扛
这里的关键不是“谁更强”,而是 把不适合 GPU 干的活,从 GPU 身上拿走。
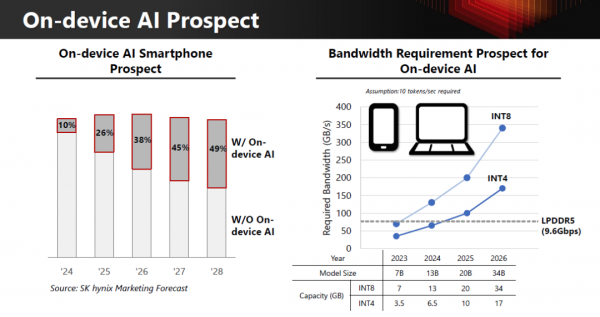
更有意思的是,SK hynix 把同一套逻辑,完整延伸到了端侧 AI。
在 on-device LLM 场景中:
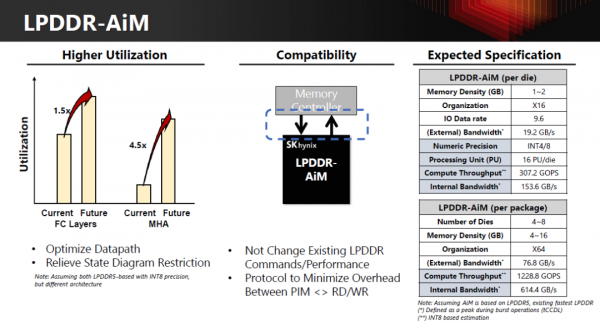
于是才有了 LPDDR-AiM 的形态:
AiM 的成立条件,来自算子结构本身,而不是某一个特定应用场景。
LLM 推理真正的天花板,不是算力墙,而是内存墙叠加能耗墙。
SK hynix 海力士 推 AiM / AiMX,并不是在“做一颗更酷的内存”,而是在尝试回答一个更根本的问题:
如果最耗带宽的计算继续远离内存,LLM 在工程和经济上,还能持续扩展吗?
至少从这套架构给出的逻辑来看,答案是否定的。
未来 AI 计算的竞争,很可能不再是谁的单点算力更强,而是 谁更早跑通“以内存为中心、按算子分工”的系统性价比。